ISM CyberRAG
Get the measurement right first, then make it inspectable.
I came into the project pushing for the team to take measurement seriously before we built anything new. That one decision shaped the rest of it. The 100-question dataset, the fixed model and embeddings across sprints, the cross-sprint comparison, and the Pipeline Explorer that lets anyone look at how the system reached an answer without opening a notebook.
What ISM CyberRAG is, in a paragraph.
The Australian Information Security Manual is Australian government cyber security guidance published by the Australian Signals Directorate. Our corpus used 25 PDF chapters with 1,073 unique control IDs, structured by applicability levels and Essential Eight maturity. It is rigorous, and it is hard to use quickly. Users such as IRAP assessors, security architects, GRC analysts, and students need a faster way to reach the right controls without losing the source evidence.
ISM CyberRAG is a deployed natural-language interface to that corpus. A user asks a question. The system retrieves the controls that actually apply, cites them, and refuses politely when a question lands outside the corpus. Three sprints of measured iteration, one fixed evaluation set, one deployed product at a public URL.
Why the ISM is hard to search, and what a RAG system helps with.
The lookup problem
Twenty-five PDFs, more than a thousand control IDs, applicability levels (Not Classified, Official, Protected, Secret, Top Secret), Essential Eight maturity tiers, revision numbers. The structure is precise. That is what makes it both useful for experts and slow for everyone else.
The people who use it (IRAP assessors, security architects, GRC analysts) often have to grep through the documents to find the right controls for a question that does not arrive in ISM vocabulary.
What we built, and what we did not
A natural-language interface that returns the right controls with citations, reducing the lookup friction. Three retrieval improvements across sprints. A two-stage guardrail that refuses out-of-scope questions politely. A deployed product anyone can use.
What I think the project contributes. The individual techniques are not new on their own. In our public search, what we did not find was an evaluated end-to-end ISM-specific system carrying this stack together: control-boundary chunking, hybrid search with cross-encoder reranking, multi-query expansion, a two-stage guardrail calibrated against real rerank-score data, and a streaming Pipeline Explorer over SSE. I would defend this as negative search evidence for our integration, not proof that nobody has built anything similar.
What this is not: a replacement for a qualified assessor, implementation advice, or a substitute for reading the ISM when a real decision is at stake. The framing is "make the document searchable", not "make the document optional".
Three sprints, three roles, three different lessons.
Every team member did Product Owner, Data Scientist, and Data Engineer once. I did them in that order. The interesting bit is not the role names. It is what each one taught me that I did not know going in.
Owning the measurement backbone
Lesson: under-scoped measurement costs more than under-scoped features. A feature can be reworked next sprint; a flaky measurement story is harder to recover from.
Building the thing I had been measuring
Lesson: teammate validation feels slower in the moment but prevents a much more expensive fix after the report is written.
Making it real and inspectable
Lesson: "CI green" is not the same as "live verified." Build status and live status are different signals; report them separately.
How the rotation worked for the whole team
| Sprint | Product Owner | Data Engineer | Data Scientist |
|---|---|---|---|
| Sprint 1 | Sreekar | Chandan | Ruben |
| Sprint 2 | Chandan | Ruben | Sreekar |
| Sprint 3 | Ruben | Sreekar | Chandan |
The seven-stage retrieval pipeline.
Pre-filter → query embedding → multi-query expansion → hybrid search (BM25 + pgvector via RRF) → cross-encoder reranking → rerank-score guardrail → LLM generation with cited ISM controls. One diagram, one pipeline, three sprints of improvements layered onto it.
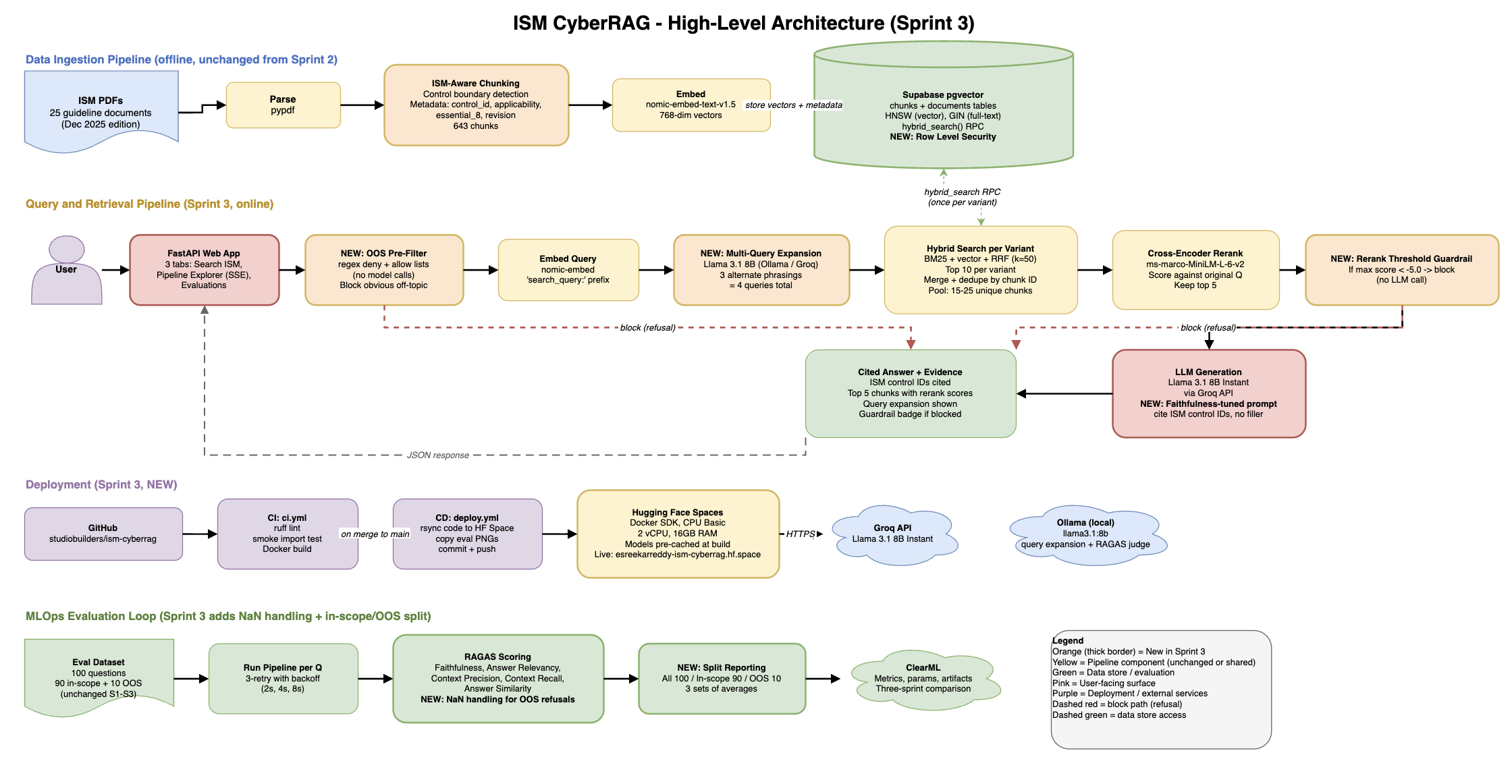
What I owned in each sprint.
Owning the measurement backbone
I expanded the evaluation dataset from 20 to 100 questions after a week-6 tutor suggestion, structured across five difficulty categories, and manually verified every ground-truth answer against the source ISM PDFs, fixing seven inconsistencies during verification. That dataset is the measurement backbone for the entire project; every cross-sprint comparison uses the same questions.
evaluations/eval_questions.json: 100-question dataset, five categories, manually verifiedsrc/evaluation.py: RAGAS wrapper, separate evaluation LLM, local-Ollama judge path- ClearML task
c32673341b364cf78c52a12992a3a6e4: Sprint 1 baseline with parameter snapshot notebooks/sprint1_poc.ipynb: runnable POC reproducing baseline end to end
Building the thing I had been measuring
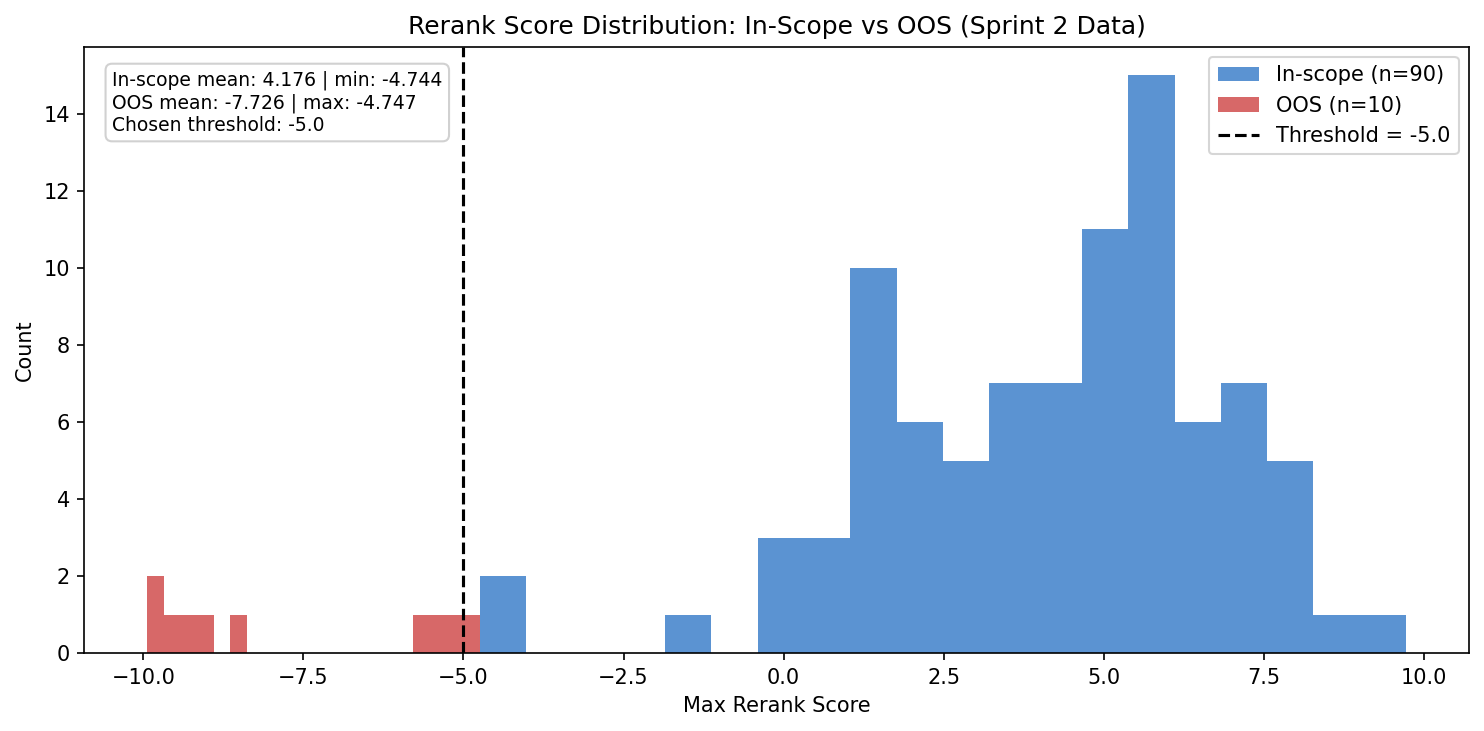
I rewrote the chunker to segment at ISM control boundaries (chunks dropped from 900 to 643, every chunk tied to a control_id), integrated a cross-encoder reranker (ms-marco-MiniLM-L-6-v2), and added answer_similarity because the standard RAGAS metrics can make correctly refused out-of-scope answers look worse than they are. I also tracked max_rerank_score per question; that calibration data became Sprint 3's rerank-threshold guardrail.
src/chunking.py: ISM-aware chunker, complete rewrite of Sprint 1's fixed-size approachsrc/reranking.py: cross-encoder rerank module, ms-marco-MiniLM-L-6-v2src/evaluation.pychanges: answer_similarity metric, max_rerank_score trackingnotebooks/sprint2_development.ipynb: sections 3, 5, 8, 8.5, 9, chunking through to the Sprint 1 vs Sprint 2 comparisondocs/sprint-2/SPRINT2_PIPELINE_REPORT.md+ ClearML task379669d5c8ca47d083bce53ab9b815fc
Making it real and inspectable
I delivered the deployment surface: Dockerfile (python:3.11-slim, CPU-only PyTorch wheels, pre-cached model weights), two GitHub Actions workflows (CI on every push, CD on merge to main), the Pipeline Explorer page driven by Server-Sent Events, the Evaluations dashboard, and the Supabase Row Level Security policy. The live URL is the evidence that this moved beyond a local demo: esreekarreddy-ism-cyberrag.hf.space.
Dockerfile: CPU-only torch wheels, pre-cached model weights, non-root UID 1000, uvicorn on :7860.github/workflows/ci.yml+deploy.yml: lint, smoke import, Docker build; rsync to HF Space on mergeapp/templates/pipeline.html+/pipeline/stream: seven SSE cards animate as the pipeline runsapp/templates/evaluations.html: three-sprint comparison + chart griddatabase/sprint3_rls.sql: Row Level Security so the publishable key cannot write to the corpus
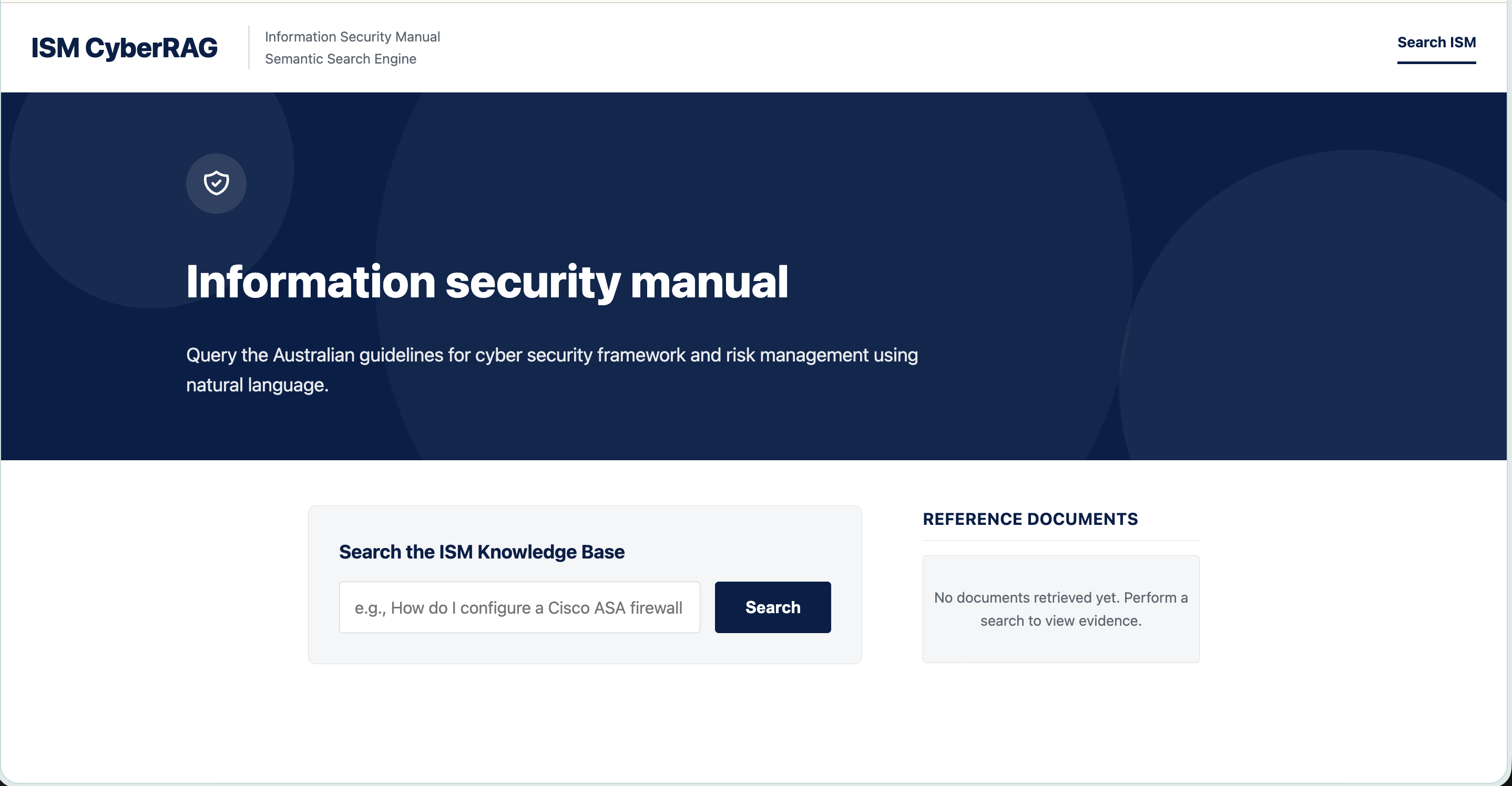
What the deployed app looks like.
The deployed app has three tabs. Search ISM returns a cited answer alongside the retrieved chunk cards. The Pipeline Explorer streams the seven pipeline stages as they happen, so a non-technical viewer can audit the system without opening a notebook. The Evaluations tab embeds the cross-sprint comparison directly.
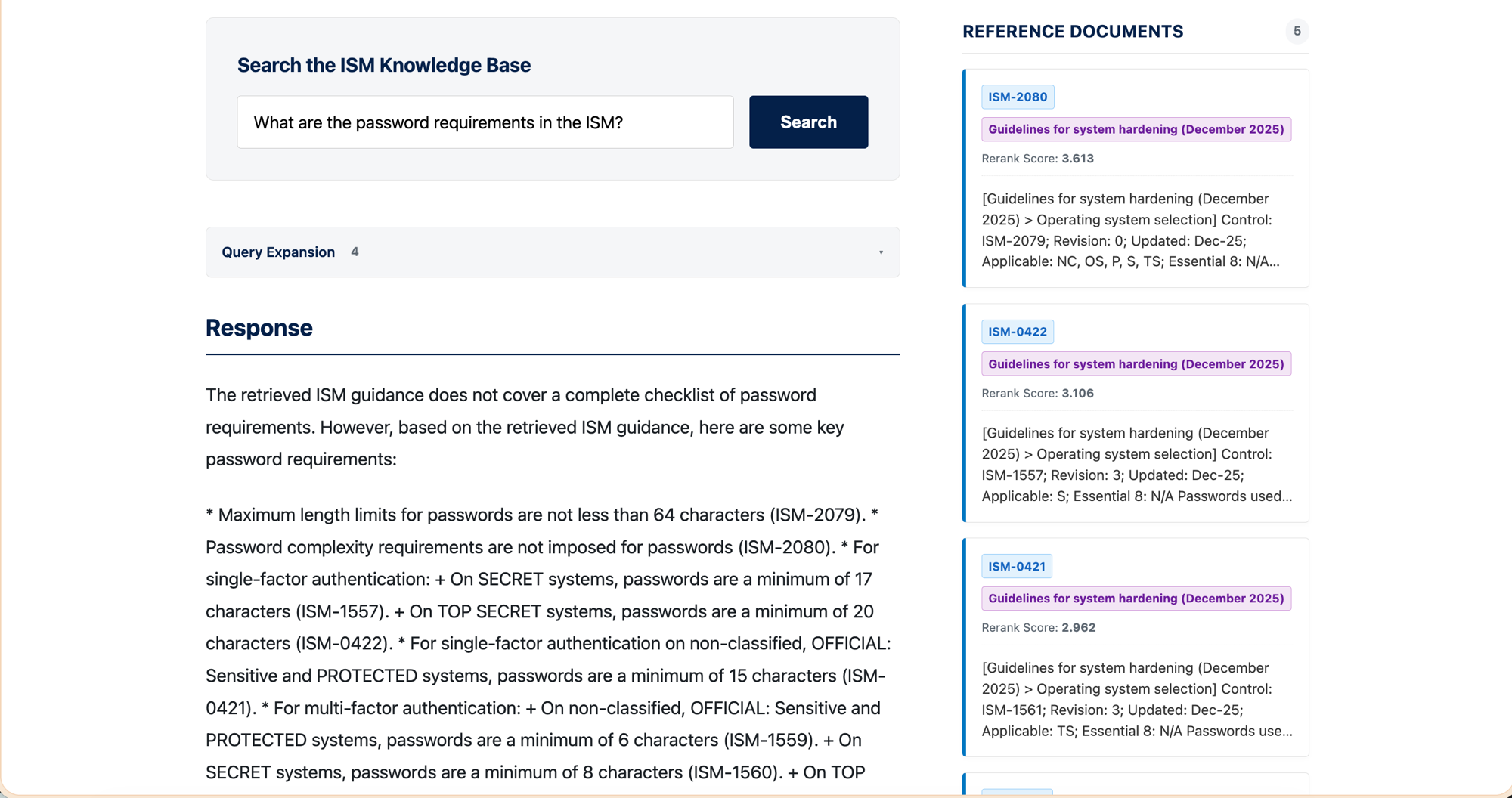
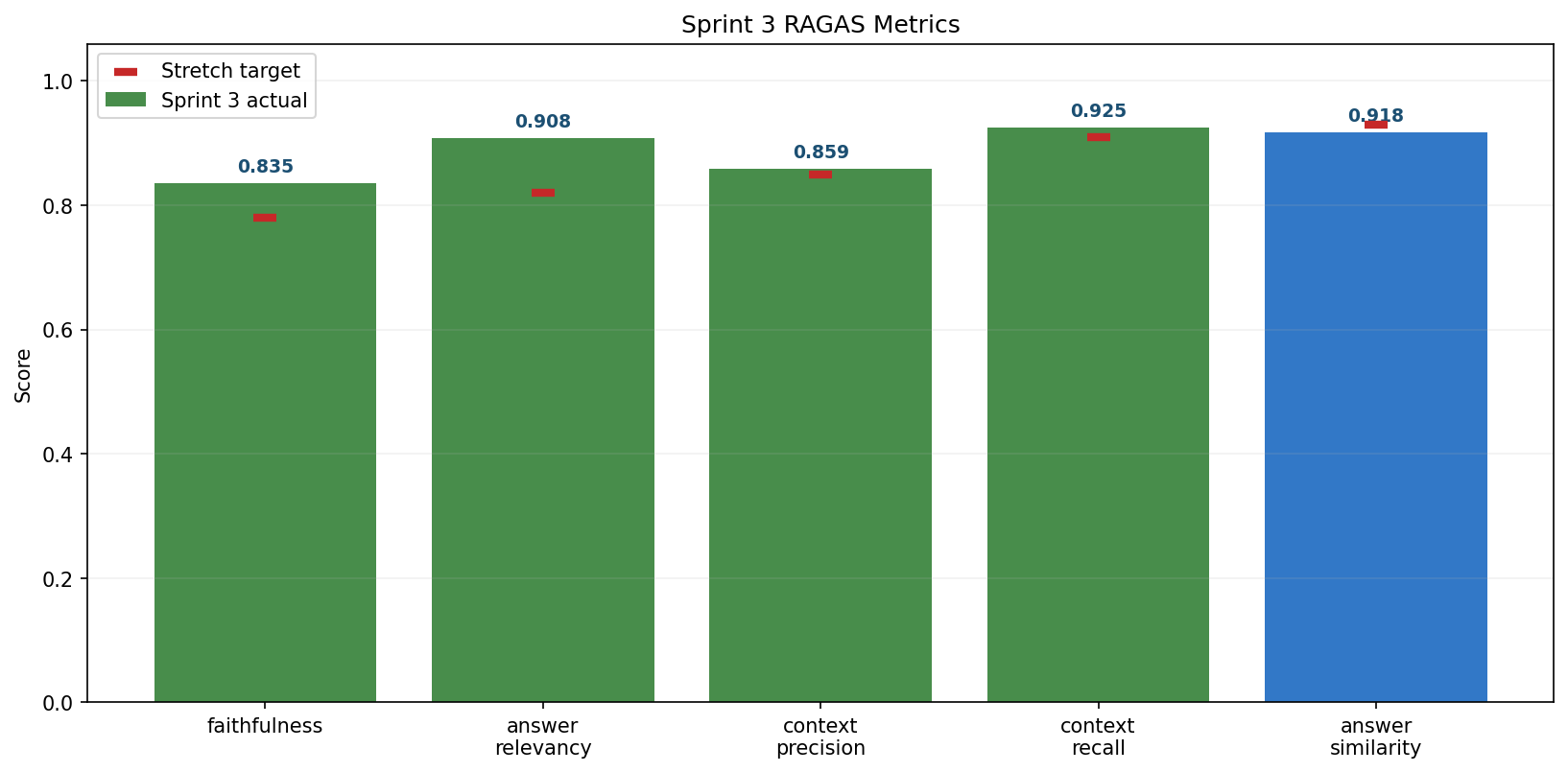
Three sprints on the same 100 questions, same generator setup, same judge.
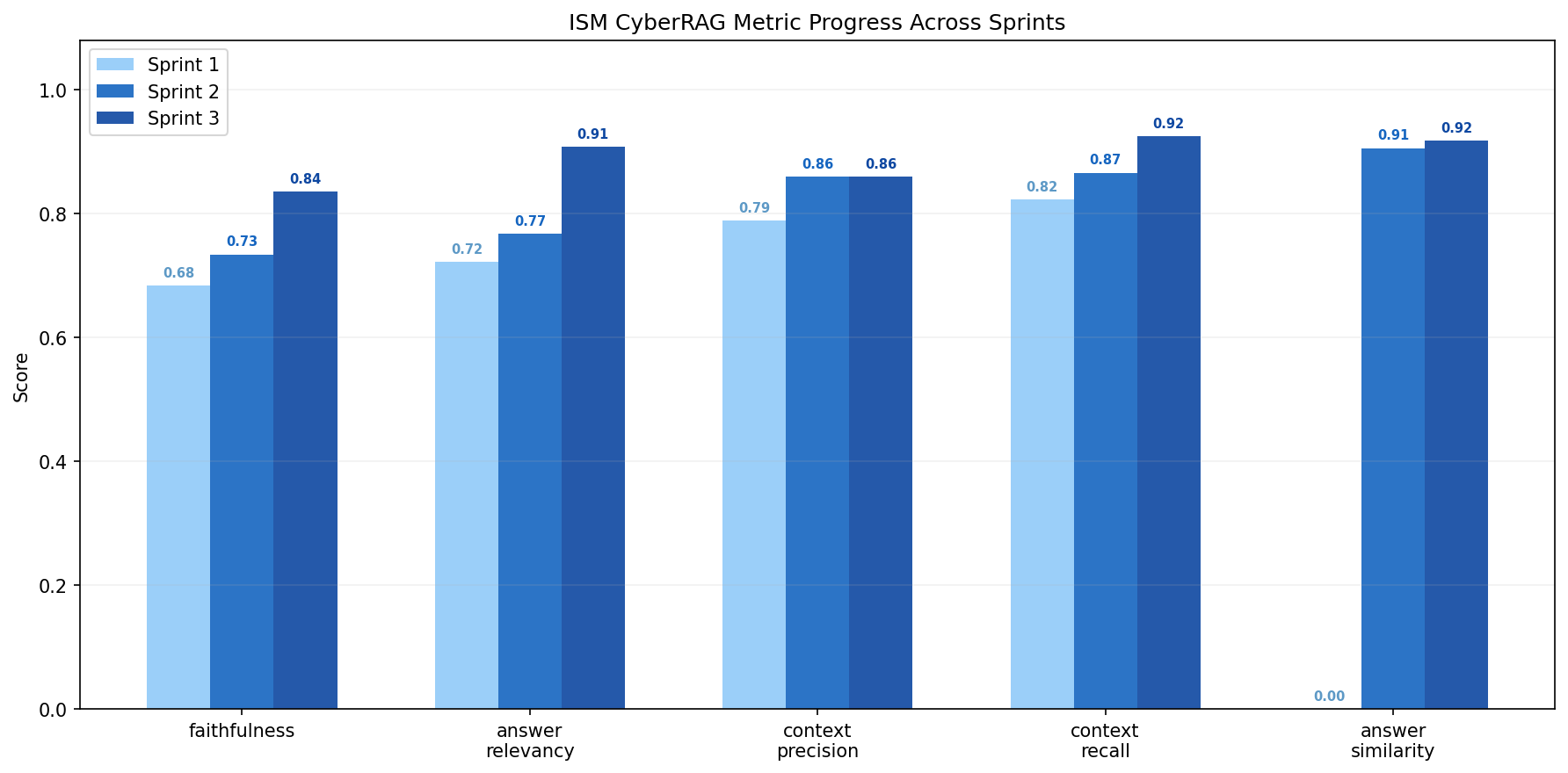
| Metric | S1 | S2 | S3 | S3 target | Result |
|---|---|---|---|---|---|
| Faithfulness | 0.6834 | 0.7341 | 0.8351 | > 0.78 | Met (+0.10) |
| Answer Relevancy | 0.7216 | 0.7678 | 0.9078 | > 0.82 | Met (+0.14) |
| Context Precision | 0.7885 | 0.8598 | 0.8590 | > 0.85 | Met |
| Context Recall | 0.8224 | 0.8659 | 0.9249 | > 0.91 | Met (+0.06) |
| Answer Similarity | n/a | 0.9057 | 0.9179 | > 0.93 | Not met (−0.012) |
Before / after: the two highest-leverage retrieval changes
Control: ISM-XXXX; Revision: X boundaries. Each chunk maps to a logical unit with structured metadata (control_id, applicability, Essential Eight level).+7.1 pp
0.7885 → 0.8598
+10 pp
0.8224 → 0.9249
Same 100 questions, same Llama 3.1 8B generator setup, same nomic-embed-text embeddings, same local-Ollama RAGAS judge across all three sprints. That makes the deltas more comparable than a one-off final score. I added answer_similarity in Sprint 2 because the standard RAGAS metrics can return NaN or 0.0 on correctly worded refusals, which makes out-of-scope handling hard to read from headline averages. The Sprint 3 evaluation fills correctly refused OOS rows to 1.0 on faithfulness, answer_relevancy and context_recall. We logged that in the release notes as a methodology choice, not buried as a metric tweak.
Three calls we made, what we rejected, and why.
SSE for the Pipeline Explorer
Data flow is one-way (server to browser) and sequential. SSE works on plain HTTP without a protocol upgrade, and I used the Fetch streaming reader so the app could send the question as POST body and parse event frames directly.
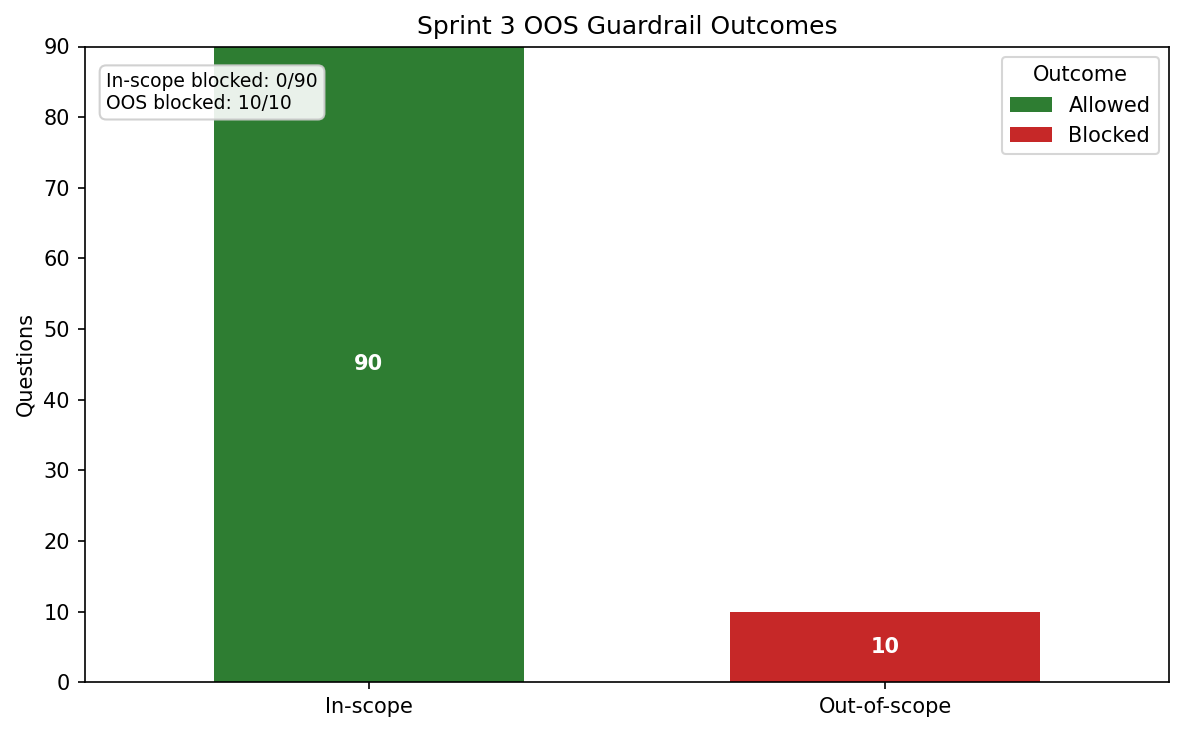
Regex + rerank-score threshold
It avoids an extra model call. The −5.0 cutoff is calibrated from Sprint 2's actual rerank-score distribution (OOS averaged −8.4, in-scope averaged positive), so the threshold is grounded in our data, not a blind hyperparameter guess.
Fill-to-1.0 on refusal NaN
Preserves the denominator and avoids making correctly worded refusals look like failed answers. Logged as an explicit methodology choice in release notes rather than buried as a metric tweak.
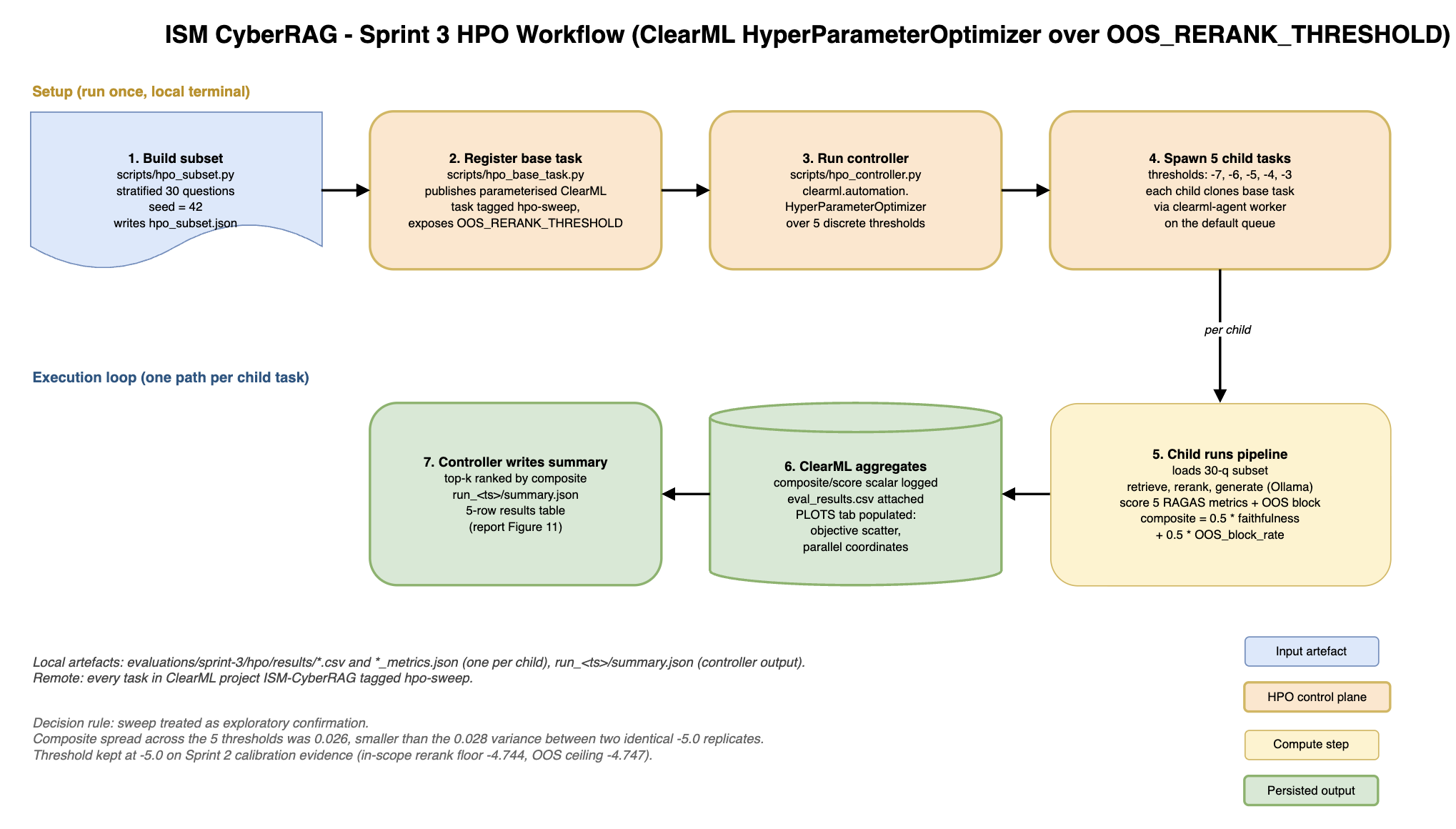
The sweep was inconclusive, and that is what we reported.
Late in Sprint 3 we wired a clearml.automation.HyperParameterOptimizer sweep over OOS_RERANK_THRESHOLD values of {−7, −6, −5, −4, −3} on a 30-question subset, with the composite objective averaged across the five RAGAS metrics.
The objective came out flat across the band, spread 0.026, with run-to-run variance of 0.028 between two identical −5.0 runs. The OOS block rate was 1.0 at every threshold because the pre-filter caught the OOS rows first.
The conclusion was not "−7.0 beats −5.0." It was "this sample size cannot distinguish thresholds in that range." We kept −5.0 because the Sprint 2 score distribution showed a narrow boundary around −4.75, and false-refusing hard in-scope ISM questions would be worse than letting the pre-filter handle obvious OOS cases.
When the variance between identical runs is bigger than the spread across configurations, the sweep is not evidence. We wrote that into the audit trail and kept the threshold the Sprint 2 score distribution already pointed to.
Three incidents that changed how I worked after them.
The pattern across these three incidents is the same: moving private work into inspectable work, in three different shapes. They are kept together because the lesson compounds across roles, not because the situations were similar.
Asking the team to trust a larger evaluation set
The tutor flagged 20 evaluation questions as too few for a defensible three-sprint comparison: per-category variance would dominate the headline numbers, and any cross-sprint deltas would be drowned out. The honest part of my response was admitting I had under-scoped the evaluation set during planning. I asked Chandan and Ruben to accept a larger measurement task close to the sprint deadline, took the work onto myself, expanded to 100 questions across five categories, and manually verified every ground-truth answer.
Accepting validation feedback on the chunker
The first ISM-aware regex worked on the sample controls I tested by hand, but Chandan's validation pass against the PDFs surfaced sections where the control-line format deviated from my assumed pattern. My first reaction was frustration; the validation was exactly what the role rotation was supposed to create.
"CI green, prod stale"
A deploy that passed CI but did not actually update the live Hugging Face Space. The rsync source path included its own destination (workflow looped until timeout); the HF README was missing required frontmatter. I had been treating green workflow status as evidence that the release was live.
Three patterns I noticed in how I work.
What I would do differently next time
What we actually did to reduce the project footprint.
Environmental
- LLM inference (Groq Llama 3.1 8B). Sticking with 8B not 70B; pre-filter blocks obvious off-topic before query expansion or final generation; rerank-threshold guardrail blocks weak-evidence before final generation; tight system-prompt instructions hold token count down. Sources: Patterson et al. (2021); Luccioni et al. (2023).
- Embedding + pgvector search. Small embedding model (nomic-embed-text, 137M parameters); one-off corpus embedding at ingestion not per query; HNSW index for sub-linear search. Sources: Strubell et al. (2019); Schwartz et al. (2020).
- Deployment + CI/CD. HF Space on CPU Basic not GPU; short CI workflow (lint, smoke import, Docker build); cached model weights in the image so cold starts do not redownload them. Source: Lannelongue et al. (2021).
Social
- Wider access to ISM guidance. A student or generalist IT worker can ask a plain question and receive a cited answer, without needing to know the document structure. Limit: reduces lookup friction, does not replace a qualified assessor. Source: Australian Signals Directorate (2025).
- Over-reliance risk. Fluent answers invite over-trust in security decisions. Response: system prompt requires citations from retrieved context, two-stage guardrail refuses out-of-scope questions, Pipeline Explorer exposes the path from query to evidence to answer. Sources: Bender et al. (2021); Bucinca et al. (2021).
- Accessibility of technical language. Natural-language search lets a generalist ask first and inspect the cited ISM control second. Limit: the app answers in English only. Sources: Australian Government Style Manual (n.d.); Australian Signals Directorate (2025).
CI, CD, experiment tracking, HPO audit trail.
.github/workflows/ci.yml: lint, smoke import, Docker build on every push.github/workflows/deploy.yml: rsync to HF Space git remote on merge to main, evaluation PNGs copied into imageevaluations/sprint-3/hpo/What the project runs on.
Each skill linked to the file or artefact that demonstrates it.
Known limits.
- Cold-start latency on HF CPU Basic. First request after idle takes longer because the container has to warm up. Mitigated for the defence demo by warming the container five minutes before, not eliminated.
- English only. We write in Australian English to match the ISM. The app does not handle other languages.
- Answer similarity short of target by 0.012. 0.9179 against a 0.93 target. We did not over-fit to close the gap.
- Single-domain corpus. The system is calibrated for the ISM. Generalisation to other security frameworks (NIST, ISO 27001) would require re-chunking, re-embedding, and re-tuning the guardrail.
- HPO sample size. The 30-question subset was too small to distinguish OOS_RERANK_THRESHOLD values in the {−7..−3} band. Larger sweep would be the natural next step.
Tickets, artefacts, identifiers, all in one place.
| Sprint | Role | Tickets | Pts | Key artefacts | ClearML |
|---|---|---|---|---|---|
| Sprint 1 | Product Owner | RAG-8, 9, 10, 11, 12, 25, 28, 29, 30, 33 | 12 + 2 | eval_questions.json · src/evaluation.py · sprint1_poc.ipynb | c32673… |
| Sprint 2 | Data Scientist | RAG-37, 38, 39, 40, 41, 42, 43 | 17 | src/chunking.py · src/reranking.py · sprint2_development.ipynb · SPRINT2_PIPELINE_REPORT.md | 379669… |
| Sprint 3 | Data Engineer | RAG-71, 72, 73, 74, 75, 76 | 14 | Dockerfile · workflows/ci.yml · workflows/deploy.yml · pipeline.html · evaluations.html · sprint3_rls.sql | sprint-3/ |
Evidence links
| Live system | esreekarreddy-ism-cyberrag.hf.space |
| GitHub repository | github.com/studiobuilders/ism-cyberrag |
| Sprint 1 ClearML task | c32673341b364cf78c52a12992a3a6e4 |
| Sprint 2 ClearML task | 379669d5c8ca47d083bce53ab9b815fc |
| Sprint 3 evaluation outputs | evaluations/sprint-3/ |
| Sprint 3 HPO outputs | evaluations/sprint-3/hpo/ |
The literature this portfolio relies on.
- Australian Signals Directorate. (2025). Information security manual (December 2025). Cyber.gov.au. https://www.cyber.gov.au/ism
- Australian Government Style Manual. (n.d.). Clear language and writing style. https://www.stylemanual.gov.au/writing-and-designing-content/clear-language-and-writing-style
- Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (pp. 610-623). https://doi.org/10.1145/3442188.3445922
- Bucinca, Z., Malaya, M. B., & Gajos, K. Z. (2021). To trust or to think: Cognitive forcing functions can reduce overreliance on AI in AI-assisted decision-making. Proceedings of the ACM on Human-Computer Interaction, 5(CSCW1), Article 188. https://doi.org/10.1145/3449287
- Es, S., James, J., Espinosa-Anke, L., & Schockaert, S. (2023). RAGAS: Automated evaluation of retrieval augmented generation. arXiv. https://arxiv.org/abs/2309.15217
- Lannelongue, L., Grealey, J., & Inouye, M. (2021). Green algorithms: Quantifying the carbon footprint of computation. Advanced Science, 8(12), Article 2100707. https://doi.org/10.1002/advs.202100707
- Luccioni, A. S., Viguier, S., & Ligozat, A.-L. (2023). Estimating the carbon footprint of BLOOM, a 176B parameter language model. Journal of Machine Learning Research, 24(253), 1-15. https://www.jmlr.org/papers/v24/23-0069.html
- Mitchell, M., Wu, S., Zaldivar, A., Barnes, P., Vasserman, L., Hutchinson, B., Spitzer, E., Raji, I. D., & Gebru, T. (2019). Model cards for model reporting. In Proceedings of the Conference on Fairness, Accountability, and Transparency (pp. 220-229). https://doi.org/10.1145/3287560.3287596
- Patterson, D., Gonzalez, J., Le, Q., Liang, C., Munguia, L.-M., Rothchild, D., So, D., Texier, M., & Dean, J. (2021). Carbon emissions and large neural network training. arXiv. https://arxiv.org/abs/2104.10350
- Schwartz, R., Dodge, J., Smith, N. A., & Etzioni, O. (2020). Green AI. Communications of the ACM, 63(12), 54-63. https://doi.org/10.1145/3381831
- Strubell, E., Ganesh, A., & McCallum, A. (2019). Energy and policy considerations for deep learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 3645-3650). https://doi.org/10.18653/v1/P19-1355